Présidentielles 2022 : À vos data !
Le 06-09-2021 Data, Visualisation, Présidentielles 11 minutes
J’ai commencé la rédaction de ma thèse à l’été 2016, pour environ un an, à l’époque où la campagne pour les présidentielles de 2017 battait son plein. Si l’écriture d’une thèse est un énorme travail, il s’agit davantage d’un marathon que d’un sprint : il faut écrire chaque jour, se relire régulièrement, se corriger, mais il est presque impossible d’y être efficace en continu. C’est également à cette époque que j’ai décidé de ne pas continuer dans la recherche académique. Il allait donc me falloir trouver un job, et je craignais que l’image du rat de laboratoire, parfois accolée à tort aux doctorants, ne m’handicape dans ma recherche. Il me fallait donc trouver un moyen de démontrer ma capacité à travailler sur des projets concrets, avec des résultats pertinents et compréhensibles.
La campagne présidentielle en cours s’est alors révélée être un parfait side-project pouvant servir à mon portfolio : je pouvais y accorder du temps de façon discontinue, je serais forcé d’avoir des résultats rapidement (et avant ma recherche effective d’emploi), et le sujet parlerait à tout le monde. J’ai donc créé un blog (un autre exercice intéressant en soi), récolté autant de données que je le pouvais, et commencé à travailler dessus.
À l’heure des présidentielles 2022, je vous propose de faire un tour de 3 sujets data que j’avais mené sur les à cette occasion, et de vous partager les réussites et les difficultés qui les ont accompagnés. Si vous êtes un étudiant en fin d’études, ou que vous comptez occuper un poste dans la datascience prochainement, ce genre de travaux fait clairement la différence parmi les nombreux CV reçus. D’ailleurs, je suis à peu près sûr que ce sont ces travaux qui m’a permis d’être retenu pour mon premier job : datascientist B2B au sein du groupe Ouest-France, chez Additi.
Projet n°1 : Suivi de la présence médiatique des candidats
Premier projet, qui peut aller du très simple au très complexe : suivre la présence médiatique des candidats. Le CSA est chargé de s’assurer du respect de l’équité de temps de parole des candidats, et avait à cette occasion publié en 2017 un suivi des temps de parole pendant la campagne. La page du CSA qui recensait ces informations a malheureusement été supprimée depuis. On pouvait néanmoins en ressortir ce type de graphe, où l’on pouvait voir la surmédiatisation logique de François Fillon lors de “l’Affaire Fillon”, mais aussi à quel point les “petits candidats” ont été absents de l’antenne.
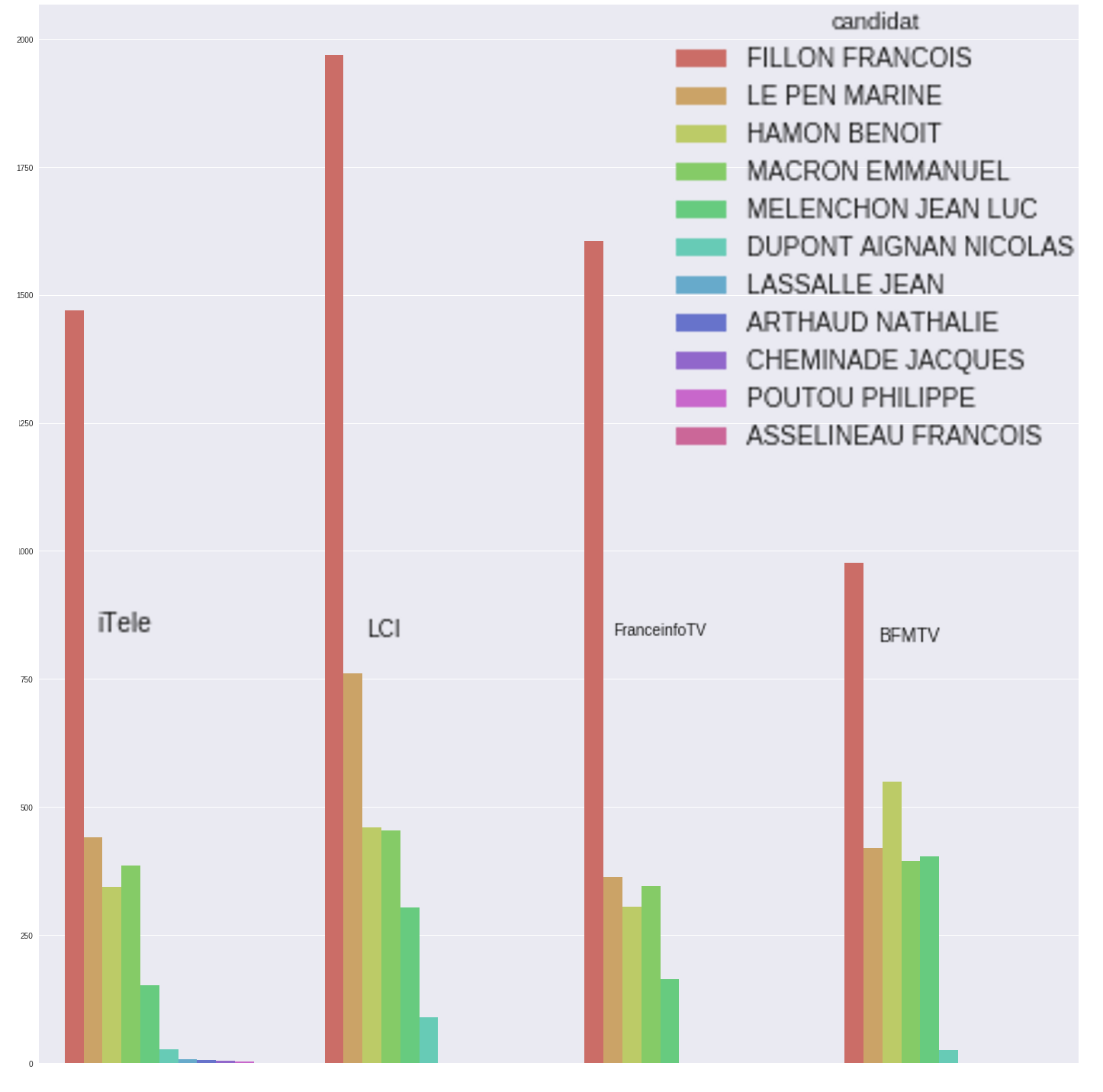 Temps de parole des candidats sur 4 chaînes début Janvier 2017
Temps de parole des candidats sur 4 chaînes début Janvier 2017
Il s’agit ici simplement de récupérer les chiffres du CSA et de les mettre en forme. On peut aller du simple bar chart présenté plus haut à des visualisations dynamiques, voire des radar charts. Attention cependant, différentes visualisations peuvent donner des effets très différents, mais c’est un bon entraînement pour repérer quels graphes sont les plus adaptés à ce genre de données.
On peut aussi vouloir aller plus loin et ne pas se contenter des chiffres fournis par le CSA. On peut pour cela s’intéresser à la presse en ligne, qui reste assez accessible. Il suffit alors de créer un programme qui récupère quelques fois chaque jour les articles des différents sites visés (un crawler), en extrait le contenu principal, et qui comptabilise le nombre de fois où le nom d’un candidat apparaît. C’est en revanche assez périlleux pour plusieurs raisons :
- chaque site a un format spécifique et il faudra adapter l’extraction du contenu principal
- le crawler peut se faire bannir
- on ne peut pas être exhaustif dans les sources.
Candidats.media, dont il ne reste que le compte Twitter, s’était essayé à cet exercice, et y avaient même ajouté une analyse automatique de sentiments afin de déterminer si les articles étaient positifs ou négatifs pour chaque candidat. Néanmoins, le choix des sources (parfois pour des raisons techniques plutôt que méthodiques), rend l’analyse complexe. Par exemple, si vous y incluez Valeurs Actuelles mais pas Médiapart (dont l’aspiration est complexe), vous aurez probablement une surreprésentation des candidats d’extrême droite.
Une autre solution est de se limiter à une source spécifique (par exemple le Reddit francophone). L’analyse n’est alors pas généralisée, mais permet de mettre en lumière de potentiels biais au sein d’une communauté restreinte.
- Les ✔️ :
- Visualisations variées intéressantes
- Présentation Intuitive, compréhensible en un coup d’oeil
- Les ❌ :
- Possibilités d’analyses limitées
- Vite biaisé si on sort des chiffres bruts du CSA
Projet n°2 : Analyses statistiques des discours et meetings
Ce qui a été le coeur de mes travaux en 2017 et que j’ai trouvé passionnant : l’analyse de discours.
J’ai pensé au début que je pourrais comparer des discours de façon unitaire, et lorsque Nicolas Sarkozy et Alain Juppé, les deux favoris de la primaire de droite, ont donné leur premier discours, d’une heure chacun, je me suis attelé à la tâche. Hélas, une heure de discours, c’est beaucoup, beaucoup trop peu pour faire la moindre analyse statistique. Les mots ne se répètaient que très peu, les thématiques abordées étaient différentes, bref, pas moyen d’en tirer grande chose sauf à faire un travail qui relève bien plus du journalisme que de l’analyse de données.
J’ai donc sorti la grosse artillerie et recensé le plus de discours possible tout au long de la campagne. J’ai utilisé des logiciels speech to text (liste ici) pour transformer les flux audio ou vidéo en texte et pouvoir mener mes analyses de façon automatique.
Cela m’a notamment servi au moment de la primaire de gauche. J’ai commencé par faire des nuages finalement assez peu convaincants. J’ai décidé d’aller plus en profondeur et de comparer les bigrammes (suites de deux mots) qui étaient prononcés fréquemment par un candidat mais presque jamais par l’autre. On pouvait alors voir que les thématiques du programme de Benoît Hamon ressortaient clairement, tandis que Manuel Valls portait un discours plus générique visant à déjà rallier pour le premier tour de la présidentielle, à laquelle sa participation lui semblait d’ores et déjà acquise.
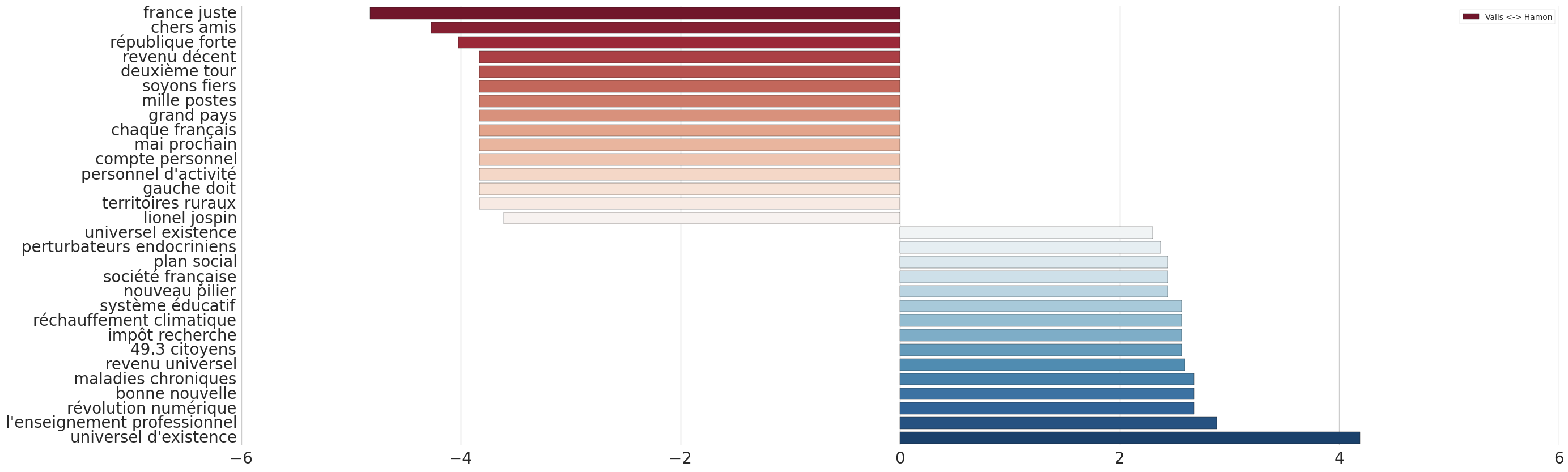 Termes employés par Manuel Valls (en rouge à gauche) et Benoît Hamon (en bleu à droite) pendant la campagne de 2017
Termes employés par Manuel Valls (en rouge à gauche) et Benoît Hamon (en bleu à droite) pendant la campagne de 2017
Je me suis également concentré sur quelques thématiques afin de vérifier si elles étaient évoquées de la même façon par les candidats. Ainsi, lorsqu’on ne regarde que les phrases qui parlent des sujets islam, laïcité, écologie, futur, santé, dette, impôts, entreprises, droite, on peut voir des différences très profondes entre les deux candidats.
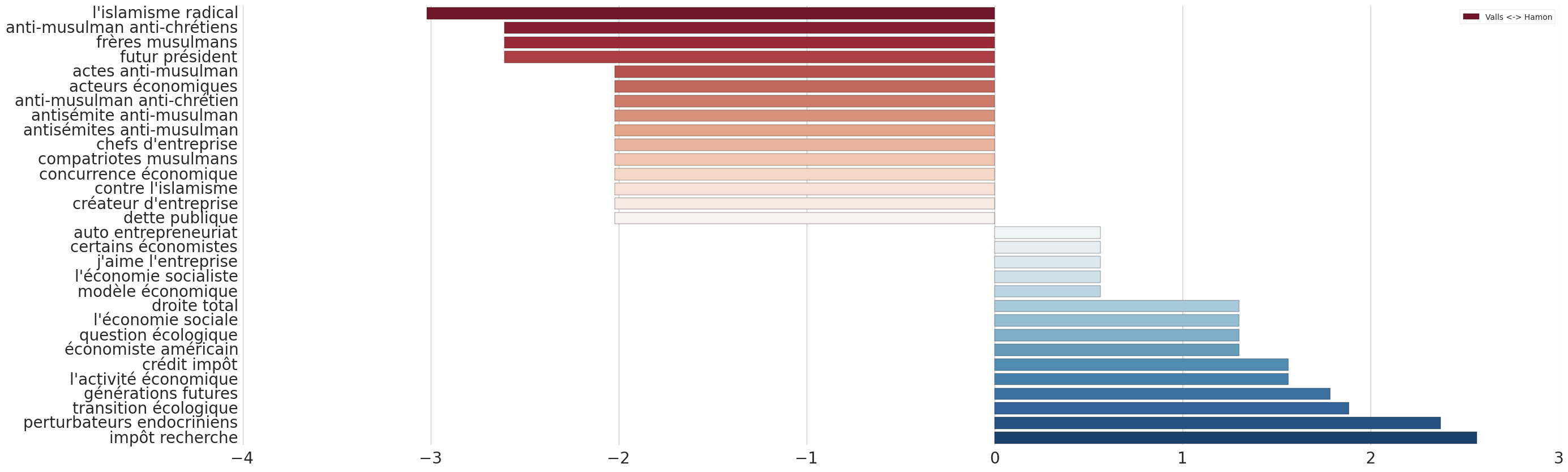 Termes employés par Manuel Valls (en rouge à gauche) et Benoît Hamon (en bleu à droite) centrés sur 8 thématiques
Termes employés par Manuel Valls (en rouge à gauche) et Benoît Hamon (en bleu à droite) centrés sur 8 thématiques
Enfin, il avait été amusant de regarder l’évolution des mots employés par Manuel Valls avant le premier tour des primaires socialistes et après :
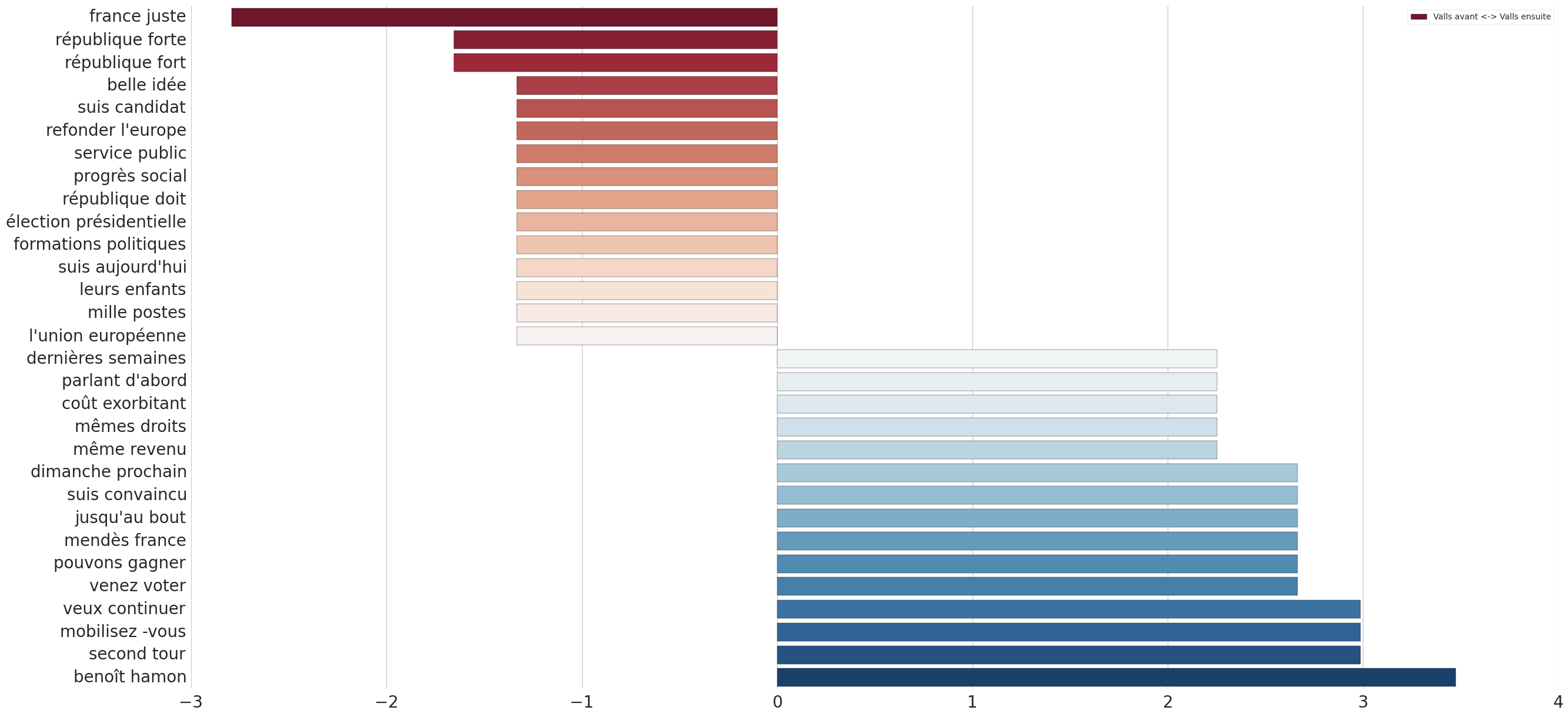 Termes employés par Manuel Valls avant le premier tour (en rouge à gauche) et après (en bleu à droite)
Termes employés par Manuel Valls avant le premier tour (en rouge à gauche) et après (en bleu à droite)
Pour 2022, le Covid rend très peu probable l’organisation de nombreux meetings comme en 2017, et il y a fort à parier que la communication sera beaucoup plus variée. Il sera donc beaucoup plus difficile d’une part de récupérer le contenu des discours, et d’autre part de comparer des registres très différents : un candidat qui ne parle pas de la même façon sur Twitch ou Tik Tok que lors d’un meeting classique. Reste à espérer que les candidats feront le travail pour nous et recenseront d’eux même l’intégralité de leurs interventions dans un seul endroit pour qu’au moins la récupération soit facilitée (certains candidats mettaient ainsi tous leurs discours sur leur compte Youtube en 2017).
- Les ✔️ :
- Beaucoup de possibilités d’analyses
- Visualisations intéressantes
- Des fun facts pas toujours pertinents mais faciles à partager
- Les ❌ :
- Volume finalement pas si élevé
- Nécessité de vérifier minutieusement ses intuitions et analyses
- Beaucoup de tuning et donc un risque de biais dans les analyses
- Difficile d’exploiter autre chose que les discours (interviews, débats, …)
- Données éparpillées, plus encore avec le Covid
Projet n°3 : Suivi des comptes Twitter
Le troisième et dernier axe d’analyse concerne l’exploitation des données Twitter des candidats. En 2017, il s’agissait du principal réseau social utilisé par les candidats. C’est moins vrai aujourd’hui avec l’utilisation de plus en plus fréquentes d’autres plateformes comme Tik Tok, Twitch, Youtube, …
J’avais très tôt aspiré grâce à leur API les données des comptes Twitter de nombreux candidats potentiels (dont la plupart n’y sont pas allés comme Michèle Alliot-Marie, Christiane Taubira ou… François Hollande) et sauvegardé les informations dans une base SQLite. Au lendemain de la primaire de droite, alors que François Fillon avait réalisé un score qui avait surpris beaucoup de monde, y compris les journalistes, j’avais remarqué qu’une hausse impressionnante du nombre de ses followers avait précédé sa victoire de quelques semaines :
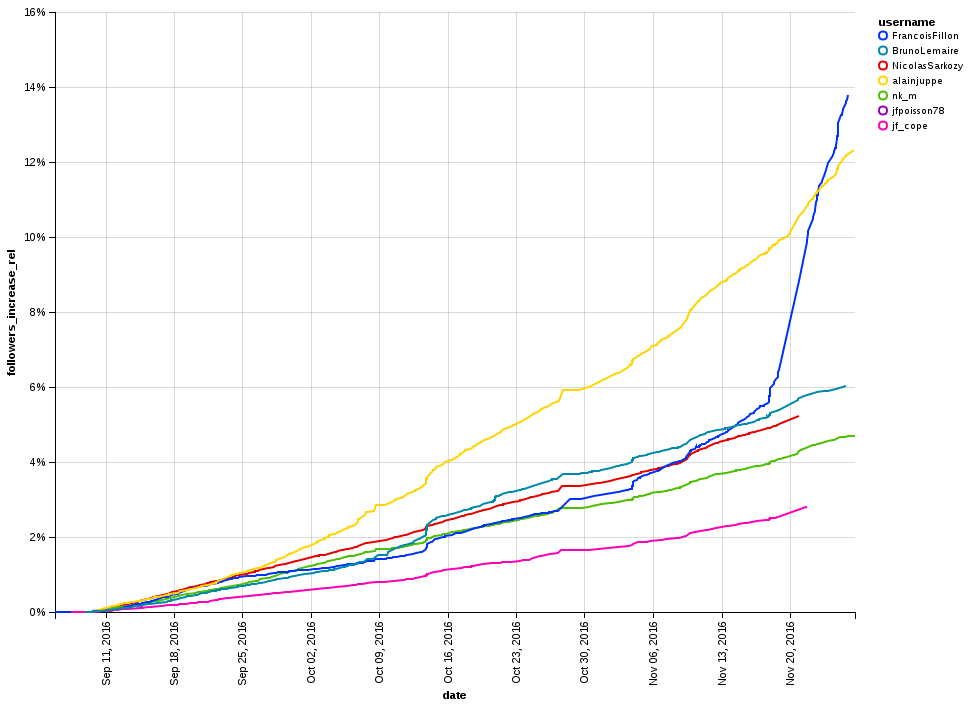 Dynamique de gain de followers sur Twitter pour les candidats de droite au moment de la primaire.
Dynamique de gain de followers sur Twitter pour les candidats de droite au moment de la primaire.
Tandis que tous les candidats étaient sur une dynamique régulière, quelques jours avant le premier tour du 20 novembre, Fillon avait décollé. Frustré de ne pas avoir vu cela dans les temps, j’ai répété l’exercice sur la primaire socialiste, et publié ce graphe à la veille du vote :
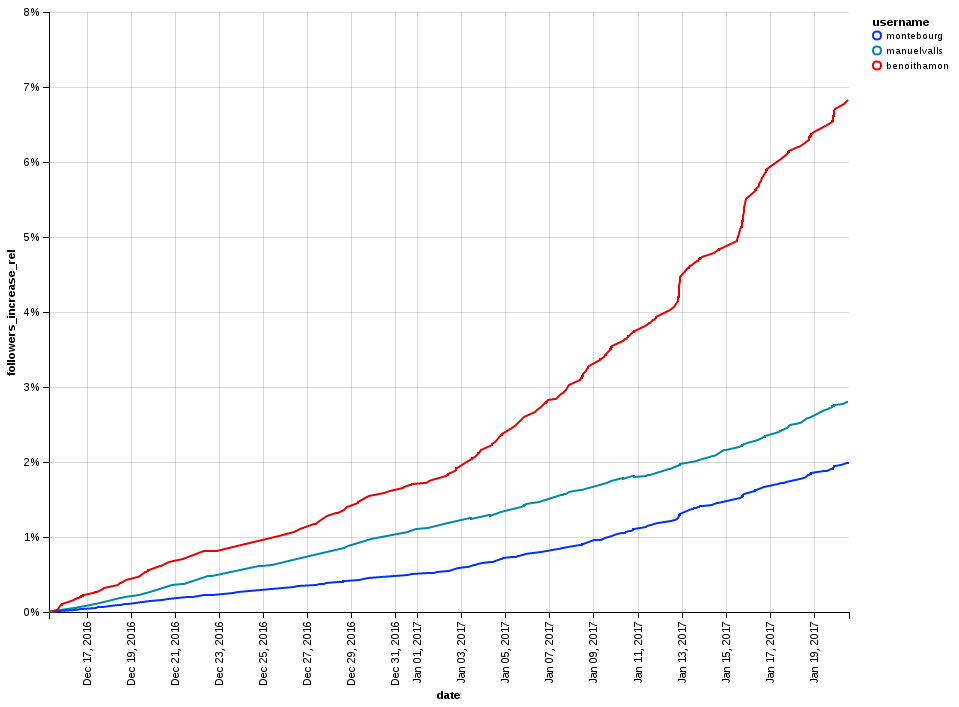 Dynamique de gain de followers sur Twitter avant la primaire socialiste pour Benoît Hamon (rouge), Manuel Valls (vert) et Arnaud Montebourg (bleu)
Dynamique de gain de followers sur Twitter avant la primaire socialiste pour Benoît Hamon (rouge), Manuel Valls (vert) et Arnaud Montebourg (bleu)
On peut y voir que Benoît Hamon bénéficiait d’une dynamique de campagne bien plus importante que ses deux rivaux, alors même qu’il était donné au coude à coude face à Arnaud Montebourg.
Contrairement à ce que ce graphe peut laisser imaginer, il ne prédisait absolument pas la victoire de Benoît Hamon face à Manuel Valls. En effet, si on pouvait aisément comparer Hamon et Montebourg qui disposaient d’une base de followers similaire avant le début de la campagne, il était impossible de les comparer à Manuel Valls qui, en tant que Premier Ministre, disposait d’un nombre bien plus élevé de followers accumulés au cours de son mandat. Afin d’obtenir le graphe présenté plus haut, il a donc fallu comparer l’augmentation relative du nombre de followers afin d’éviter ces effets de popularité pré-élections.
- Les ✔️ :
- Travail de récolte intéressant (APIs, filtres, …)
- Des effets parfois pertinents
- Les ❌ :
- Difficile de comparer certains candidats entre eux
- Présence de bots risquant de biaiser fortement les résultats
Conclusion
Les présidentielles sont le moment idéal pour mettre à l’épreuve ses compétences en datascience. Elles obligent à obtenir des résultats dans un temps court et à aller chercher soit même des données souvent éparpillées qu’il faut stocker, structurer, organiser afin de pouvoir s’en servir de façon fiable plusieurs semaines ou mois plus tard. Elles obligent à de l’inventivité afin de prodfuire des analyses originales, poussent à mettre en place une plateforme permettant de partager ses résultats (Medium, Blogger ou site custom comme ce blog), à réfléchir aux meilleures visualisations possibles, et permettent de progresser à la fois sur le plan technique, méthodique, et communicationnel.
J’espère que ce retour sur mes expérimentations de 2016-2017 vous auront donné envie de vous investir dans l’analyse des élections de 2022 !
